
|
Kodni sistem Slovenska knjizevnost Avtorji Urednistvo <-> bralci |
Jezik in slovstvo Razprave in clanki |
Jezik in slovstvo Kazalo letnika Zadnja verzija |
| Tomaz Erjavec | UDK 81:681.3 |
Racunalniske zbirke besedil
Korpus je zbirka besedil, ki so izbrana tako, da karakterizirajo stanje ali raznovrstnost nekega jezika. Uporaben je kot osnova, na kateri gradimo opise jezika, ali pa kot sredstvo za preverjanje hipotez o jeziku. Korpusi so dandanes ze standardno shranjeni na racunalnikih, saj ti po eni strani omogocajo kompaktno in poceni hranjenje ter razpecevanje ogromnih kolicin besedil, po drugi strani pa ta besedila lahko z njimi bolj ucinkovito izkoriscamo. Uporabnost nekega korpusa je odvisna od njegove velikosti pa tudi urejenosti, tj., kako podrobno je dokumentiran in oznacen, ter standardiziranosti njegovega zapisa.
Veja jezikoslovja, ki je korpuse tradicionalno uporabljala, je leksikografija; pri izdelavi slovarjev metode introspekcije ne zadoscajo in se je nujno opreti na govor (parole). V formalnem in racunalniskem jezikoslovju ta pristop ni nujno edini.
1.1 Nekaj zgodovine
Dejavnikov, ki so v osemdesetih letih vplivali na ponovni prodor empiricno podprtega jezikoslovja, je vec. Programi za skladenjsko analizo so sicer lahko minuciozno razclenili neki tocno dolocen stavek, vendar pa so dosegali zelo slabe rezultate na odprtem besedilu. Razlog za to je bil predvsem v premajhnem pokritju njihovih slovarjev in pravil, pri cemer pa je izdelava teh podatkov izredno zamudno pa tudi zahtevno delo. Ta problem, t. i. ťknowledge acquisition bottleneckŤ, je tipicen ne samo za racunalnisko jezikoslovje, pac pa tudi za vecino podrocij umetne inteligence. Postalo je jasno, da je za napredek tega podrocja potrebno zaceti zajemati vire informacij o domeni obravnave (npr. o onesnazenosti jezer ali diagnozah pacientov) in se na njihovi osnovi (pol)avtomatsko uciti zakonitosti, ki v tej domeni vladajo. V racunalniskem jezikoslovju so taksni jezikovni viri se posebej kompleksni in je njihovo zbiranje temu primerno tezje, s cimer postane tudi rezultat toliko pomembnejsi. Zbiranje se je osredotocilo na bolj ali manj formalno zapisane racunalnisko berljive slovarje, predvsem pa na korpuse kot osnovne vire jezika.
Obenem je nova generacija programov, ki temeljijo na statisticnih zakonitostih besedila, pokazala obetavne rezultate. Ti programi so po svoji naravi sicer nepopolni, so pa bolj robustni in imajo v povprecju precej vecje pokritje od simbolicnih pristopov, poleg tega pa se lahko ucijo iz primerov. Lazje je rocno oznaciti neko besedilo, na katerem se bo program ucil, kot pa pisati pravila, ki naj bi te oznacbe zagotovila. Poleg tega je rocno oznacen ali pregledan jezikovni vir lahko koristen tudi za druge namene, rocno napisana pravila pa uporabna samo skupaj s programom, za katerega so bila napisana.
To nas pripelje do pomembne razlike med racunalniskimi korpusi petdesetih let in sedanjimi korpusi. V pedesetih letih so bila besedila tipicno zbrana za neki povsem dolocen namen in v formatu, ki ga je podpirala programska oprema, ki naj bi besedilo obdelala. Ker jezikovni viri danes pomenijo dragoceno blago, ki ga je potrebno ohraniti pa tudi siriti, se v njihovo izdelavo vlaga vec truda, zapisuje pa se jih v skladu z mednarodnimi standardi in priporocili.
Nenazadnje je bliskoviti dvig kolicine in kvalitete racunalniskih korpusov pripisati tudi tehnoloskemu napredku na podrocju racunalnistva in z njim spremembi glavne namembnosti racunalnikov. Racunalniki se vedno bolj uporabljajo kot orodje za procesiranje besedil, s cimer postaja jezikovni inzeniring profitno podrocje, obenem pa se zacenja vprasanje ťracunalniske pismenostiŤ nekega jezika povezovati z njegovo identiteto. Programi, ki naj bi pomagali pri pripravi, izmenjevanju, urejanju, predstavitvi in dostopu do jezikovnih informacij za neki jezik, tipicno potrebujejo urejene vire znanja o tem jeziku. Do taksnih virov najlaze pridemo s pomocjo besedilnih zbirk. Obenem je vse vec besedil dostopnih neposredno na racunalnikih in jih je temu primerno lazje pretvoriti v korpus.
V ilustracijo napredka racunalniskih korpusov lahko primerjamo velikost prvega oznacenega referencnega korpusa z danasnjimi korpusi (britanske) anglescine. Korpus LOB (Lancaster-Oslo/Bergen) [6], izdelan leta 1986, je vseboval milijon besed, korpus BNC (Brittish National Corpus), izdelan leta 1994, pa sto milijonov besed --- v tiskani obliki bi ta besedila zavzela priblizno deset metrov polic. Na kolicino korpusov in zanimanje zanje kaze tudi ustanovitev 'borkerskih his' za korpuse in druge jezikovne vire. Tako je bil leta 1992 v Zdruzenih drzavah z vladno podporo ustanovljen Linguistic Data Consortium, ki zdruzuje v svoji ponudbi preko stirideset pisnih in govorjenih korpusov ter slovarskih baz. Pred nedavnim je tej pobudi sledila tudi Evropska unija s financiranjem ustanovitve organizacije ELRA (European Linguistic Resources Association).
Kolicina in raznovrstnost jezikovnih virov je seveda najvecja za anlgeski jezik. V zadnjih desetih letih je bilo mnogo taksnih virov, na prvem mestu korpusov, izdelanih tudi za jezike Evropske unije, k cemur so v veliki meri prispevale tudi iniciative Evropske unije. Za jezike vzhodno- in srednjeevropskih drzav je stanje slabse in obenem precej raznovrstno. Dolocene drzave imajo na podrocju (racunalniskega) jezikoslovja ze dolgo tradicijo (npr. Ceska in Madzarska), kar se odraza tudi v stanju njihove jezikovne infrastrukture. Tako imajo npr. na filozofski fakulteti v Pragi ze oddelek, katerega edina naloga je zagotoviti 20 milijonov besed velik referencni korpus, ki bo nato podlaga novemu slovarju ceskega jezika.
V Sloveniji dostopnih in obenem standardiziranih jezikovnih virov se nimamo. Edini javni referencni korpus slovenskega jezika [16] je precej majhen, obstaja samo v knjizni obliki in je star dvajset let. Svetla izjema tega stanja so na WWW objavljena besedila slovenskih klasikov [9], ki imajo prednost, da so dostopna in ze do precejsnje mere urejena, ravno tako pa, glede na svojo starost, vecinoma ne podlezejo vec zakonu o avtorskih pravicah. Vendar pa ravno zaradi starosti besedil ne podajajo slike sodobnega slovenskega jezika. Dosti slovenskih besedil, ki bi bila lahko osnova za korpuse, obstaja seveda tudi v racunalniski obliki, vendar pa niso standardizirana, predvsem pa je njihova dostopnost omejena na institucije, ki so jih proizvedle (npr. zalozbe, casopisne hise), ali pa na institucije, ki so sodelovale v njihovi pripravi.
1.2 Tipologija korpusov
Po tipologiji Eagles [14] so karakteristike nekega korpusa naslednje:
In kje so korpusi pravzaprav uporabni? Najbolj evidentno podrocje je seveda slovaropisje. Prvi slovar, izdelan izkljucno na osnovi racunaliskega korpusa, je bil Collinsov CoBuild English Language Dictionary iz leta 1987 [13]. Danes je uporaba racunalniskih korpusov v angleskih leksikografskih hisah ze standardna, posebej se za specializirane slovarje. Tako npr. v Cambridge University Press pri izdelavi ucnega spansko-angleskega slovarja uporabljajo korpus popravljenih nalog spanskih ucencev anglescine, saj te najbolje pokazejo tipicne napake, na katere lahko slovar potem opozori.
Uporaba korpusov je se posebej zanimiva za dinamicna in z gospodarstvom neposredno povezana podrocja jezika, kot je terminologija. V korpusih lahko odkrijemo ze uporabljene termine, njihove prevode ali razlage, s cimer je omogoceno bolj azurno in cenejse izdelovanje slovarjev.
Ena prvih moznih uporab korpusa je za raznovrstne (formalne, socialne, literarne) jezikoslovne studije, predvsem za preverjanje teorij o jeziku skozi iskanje distribucije in konkretnih primerov izbranih pojavov. To velja toliko bolj za jezikovno ali kako drugace oznacene korpuse. V primerjavi z neobdelanim besedilom lahko v oznacenem korpusu iscemo bistveno bogatejse vzorce. Tako bi npr. za skladenjske raziskave bil zanimiv korpus, v katerem so besede oblikoslovno oznacene, za sociolingvisticne pa npr. korpus, kjer je premi govor oznacen s spolom govorca.
Nenazadnje so racunalniski korpusi pomembni za razvoj podrocja jezikovnih tehnologij, pa ce so to pripomocki za avtorje, ucenje jezikov ali prevajanje, programi za analizo in sintezo govora itd. Vsi taksni programi potrebujejo 'zavest' o jeziku, pri katerem naj bi bili v pomoc, potrebujejo torej racunalniske jezikovne vire: slovarje, pravila in distribucije elementov dolocenega jezika. Mnogo teh virov je mogoce (pol)avtomatsko zajeti iz korpusov.
Standardi in oznacevanje korpusov
Na prvi pogled ravno racunalniki zadovoljujejo ti dve zelji, saj je razmnozevanje racunalniskih podatkov, za razliko od ostalih dobrin, prakticno zastonj, digitalna informacija pa ne podleze zobu casa. Vendar morajo biti racunalniski zapisi podrobno definirani, obenem pa so racunalniki predmet bliskovitega tehnoloskega razvoja. Zaradi tega se izkaze, da imajo besedila, hranjena na racunalniskih medijih, zaenkrat bistveno manjso izmenljivost in trajnost kot pa tiskana besedila.
Problemi digitalnega zapisa besedil se zacnejo ze pri zapisu crk. Popolna racunalniska podpora in soglasje o naborih znakov obstaja samo za anglesko abecedo, medtem ko bomo v Sloveniji nasli deset nacinov, kako zapisati c, s in z. Ker se vedno vec besedil, ki sestavljajo korpus, zajema neposredno iz digitalnih virov, je problem razlicnih formatov dokumentov se posebej perec; ce se razlikujejo ze zapisi crk, so toliko bolj razlicni nacini zapisa odstavkov, premega govora, naslovov, opomb, bibliografskih podatkov itd. Razlikujejo se glede na programsko opremo, s katero je bilo besedilo narejeno, po videzu, kakrsnega naj bi imelo tiskano besedilo, in glede na osebo, ki je besedilo napisala. Vendar so vsi ti podatki v korpusu vsaj potencialno pomembni, saj tvorijo del besedil, ki jih hocemo zajeti. Ce v korpusu niso enotno in prepoznavno oznaceni, bo ta informacija izgubljena za uporabnike korpusa.
Cetudi nam uspe pri izgradnji korpusa to zmedo na nasem racunalniku v lastno zadovoljstvo urediti, bodo na drugih racunalnikih z drugimi operacijskimi sistemi in drugimi programi podatki vseeno neuporabni ali pa bodo vsaj zahtevali veliko truda za njihovo konverzijo v ciljni zapis. V primeru, da korpus se dodatno oznacimo (npr. s skladnjo, prevodi, leksikografskimi podatki), bo problem seveda se bistveno hujsi. Izmenljivost taksnih zapisov je majhna.
Podobno majhna je tudi trajnost racunalniskih podatkov: besedila na petnajst let starem magnetnem traku so danes tezko uporabna, podobno tudi besedila, napisana na urejevalniku teksta iz tistega casa. Ne enih ne drugih danes ne moremo vec brati ali pa je v to potrebno vloziti precej truda.
Edino standardizacija lahko resi problem izmenljivosti in trajnosti digitaliziranih besedil. Poglavje v nadaljevanju obravnava tri nivoje tega procesa. Z osnovno in najbolj natancno definirano stopnjo racunalniskega zapisa strukture besedil se ukvarja standard SGML (Standard Generalized Markup Language) mednarodne organizacije za standardizacijo ISO (International Organization for Standardization). Z zapisom in konkretnim oznacevanjem strukture besedil predvsem za namene znanstvene obravnave jezika se ukvarjajo s SGML skladna priporocila iniciative za oznacevanje besedil TEI (Text Encoding Initiative). Konkretno obliko zapisa racunalniskih korpusov za namene jezikovnih tehnologij pa podaja s TEI skladen zapis z imenom CES (Corpus Encoding Standard), ki nastaja oz. je nastajal v okviru evropske iniciative Eagles ter projektov MULTEXT in MULTEXT-East.
2.1 Standardni posploseni jezik za oznacevanje
SGML je prvenstveno jezik za oznacevanje dokumentov, pri cemer lahko oznake opisujejo kakrsnokoli informacijo, ki je dodana osnovnemu besedilu, npr. podatek, da je neki niz v besedilu naslov, ime ali beseda, da je neka beseda glagol, da ima neki termin povezavo s svojo razlago, da neki stavek spremlja slika ali njegov prevod in da nek monolog govori Hamlet v prvem dejanju neke tragedije.
SGML se glede na ostale jezike za oznacevanje dokumentov odlikuje v treh karakteristikah:
Poudarek na opisnem namesto postopkovnem oznacevanju.
Koncept tipa dokumenta.
Neodvisnosti od konkretnega zapisa besedil.
2.2 Iniciativa za zapis besedil
TEI je kot osnovo svojega zapisa vzel SGML. TEI P3 je nabor definicij tipov dokumentov in entitet, ki za siroko paleto zvrsti besedil doloca konkretne oznake in njihovo strukturo. Skorajda bolj pomembnih pa je 1200 strani dokumentacije, ki podaja pomen posameznih oznak, opisuje DTD-je ter izpelje nacin za njihovo kombiniranje ter nadgradnjo.
TEI P3 pozna tri vrste naborov oznak, ki jih sestavljamo v t. i. modelu Chicago pice. Vsaka pica ima dve nujni sestavini: paradiznik in sir. Podobno TEI loci srediscne oznake (core tags), ki so obvezne v vseh s TEI skladnih dokumentih. Srediscne oznake dolocajo nabore znakov, glavo dokumenta ter oznake, ki so na voljo v vseh TEI dokumentih, npr. oznake za naslove in odstavke.
Vsaka pica ima tudi testo kot osnovo, vendar se njegova zvrst (vsaj v Chicagu) lahko izbere: lahko je tanko in hrustljavo, lahko debelo in mehko, ne more pa biti oboje hkrati. Podobno se tudi besedila delijo na razlicne zvrsti, ki so med seboj razmeroma dobro locene. Osnovni nabori oznak (base tag sets) v TEI P3 obsegajo osnovni nabor za leposlovje, poezijo, gledalisce, zapis govora, tiskane slovarje ter terminoloske baze.
Koncno imajo pice lahko tudi enega ali vec dodatkov, TEI pa dodatne nabore oznak (additional tag sets). Ti opisujejo raznovrstna dodatna oznacevanja, ki ponavadi predstavljajo doloceno interpretacijo besedila ali pa netekstualne elemente besedil, kot so navzkrizne povezave (za stvarna kazala) ali pa slike. Takih naborov je vsega skupaj devet, med njimi so nabor za analiticne mehanizme (npr. skladenjsko analizo), nabor za dokumentiranje uredniskih posegov, nabor za imena in datume ter nabor za jezikovne korpuse.
Za konec poglejmo v sliki 1 se primera dveh delov dokumentov, ki sta zapisana v standardu SGML in skladno s priporocili TEI. Na levi je primer besedila, oznacenega s skladenjsko analizo, na desni pa del glave dokumenta, ki bi bila uporabna za zapis radijskih porocil. Bralec bo opazil, da so TEI oznake angleske: ceprav je v TEI obliki mozno strukturirati zapis poljubnega jezika, ostaja metajezik zapisa angleski.
Vsi veliki korpusi, izdelani v zadnjih nekaj letih, so, ce ze ne dosledno sledili, vsaj upostevali TEI priporocila, saj so le-ta najbolj podrobna in natancna dolocila za oznacevanje jezikovnih virov.

Slika 1: Primera TEI oznacenih dokumentov.
2.3 Standard za zapis korpusov
CES doloca osnovni zapis in obseg oznacevanja, ki ga mora korpus zadovoljiti, da ga lahko se smatramo za standardiziranega. CES opredeli tri nivoje take standardizacije, kjer vsak visji nivo dodatno standardizira korpus:
1. CES-1 dokument ima s TEI skladno glavo, tj. bibliografske in ostale podatke o korpusu, telo dokumenta pa je oznaceno, v skladu s CES-definicijo dokumenta, z osnovno strukturo, tj. z glavnimi razdelki besedila do nivoja odstavkov.
2. CES-2 dokument ustreza nivoju CES-1, poleg tega pa vsebuje TEI oznake, na katere se lahko sklepa iz tipografskih informacij v originalnem besedilu: premi govor, imena, stevilke, datumi itd.
3. CES-3 dokument mora vsebovati CES-2 oznake, polega tega pa ustreza dodatnim zahtevam za oznacevanje stavkov in premega govora. Vse izkljucno tipografske informacije so odstranjene iz besedila in kvecjemu ohranjene kot vrednosti atributov.
4. Nivo jezikovnega oznacevanja: poleg osnovnih nivojev je korpus mozno tudi dodatno oznaciti z jezikovnimi informacijami. CES obravnava dvoje taksnih oznacevanj, in sicer oblikoslovno oznacevanje besed in pa zapis poravnav v vzporednem korpusu, tj. zapis poravnave nekega elementa v originalu z njegovim prevodom.
3 Procesiranje korpusov
V izdelavi korpusa je (1) dobljena besedila najprej potrebno urediti in strukturno oznaciti, s cimer dobimo ekvivalent CES-2 oz. CES-3 standardiziranega korpusa. Korpus lahko (2) s pomocjo oznacevalcev se dodatno oznacimo z jezikovnimi podatki. Ta dva koraka zahtevata precejsen vlozek cloveskega dela, saj je podatke tu potrebno rocno vnasati ali pa vsaj preverjati. Vendar pa tako pridobimo dokumentiran in standardiziran jezikovni vir, ki je izmenljiv in ga lahko s siroko dostopnimi orodji uporabljamo v raznovrstne namene.
Ker orodja za izkoriscanje korpusov dostikrat zahtevajo besedila v sebi lastnem formatu, je korpus (3) iz standardiziranega formata potrebno najprej pretvoriti v format orodja. Vendar pa je, za razliko od procesa izdelovanja korpusa, ta korak preprost in popolnoma avtomatski. Zadnji korak je seveda (4) dejanska uporaba korpusa s pomocjo ustreznih programov.
V nadaljevanju poglavja najprej obravnavamo orodja, ki imajo neposredno zvezo s SGML (1 in 3), nato (2) jezikovne oznacevalnike in koncno (4) pregledovalnike korpusov.
3.1 Orodja SGML
Ko je korpus vsaj v minimalnem zapisu SGML, je nad njim ze mogoce uporabljati orodja SGML. Programsko opremo, ki se 'zaveda' standarda SGML, je mogoce kupiti, kar nekaj taksnih programov ali pa knjiznic pa je tudi prosto dostopnih. Osnovno orodje je razclenjevalnik SGML, ki preveri, ali je neki dokument SGML v skladu s svojo definicijo tipa, in definira vsak element glede na njegovo mesto v tej definiciji. Ostali razredi programov SGML omogocajo enostaven vnos dokumetov SGML, iskanje podatkov v dokumentih ali pa pretvorbo iz zapisa SGML v ciljni zapis, npr. za tiskanje ali predstavitev na WWW, ali pa za prevedbo v neko specificno obliko, ki jo pozna nase orodje za pregledovanje korpusov.
Ker TEI zapis vsebuje vec eksplicitne informacije kot pa originalni zapis, je v taksno konverzijo potrebno vloziti sorazmerno dosti dela: cetudi so na voljo programi, ki bi konverzijo avtomaticno opravljali, ti niso nezmotljivi, poleg tega pa prevod v rigorozni zapis SGML pogosto razkrije napake in nekonsistence v originalnih besedilih --- taksne napake lahko bodisi popravimo bodisi oznacnimo kot napake.
Dodatno jezikovno oznacevanje se sicer tudi lahko ze dogaja v SGML, vendar je poudarek pri tem ze na jezikovnem znanju teh orodij, zato so obravnavana v naslednjem razdelku.
3.2 Jezikovno oznacevanje
Kaj tocno hocemo v besedilu oznaciti, je seveda odvisno od namembnosti korpusa. Tu bomo omenili dva programa, ki sta se posebej zanimiva za jezikoslovne in slovaropisne obravnave. Prvi oblikoslovno oznaci besede v besedilu, drugi pa stavcno poravna vzporedni korpus, oba pa spadata v razred programov, ki izkoriscajo statisticne lastnosti jezika. Kot je bilo ze omenjeno, so taksni programi v zadnjem casu predmet velikega zanimanja [2], saj so robustni in se lahko ucijo ob rocno oznacenih besedilih.
Za oblikoslovno oznacevanje besed v korpusu je potrebno najprej imeti slovar ali pa program, ki za besedne oblike doloci njihove mozne oblikoslovne oznacbe. Vendar pa ima neka besedna oblika tipicno vec moznih interpretacij: tako je npr. beraci lahko glagol v velelniku ali povedniku, ali pa samostalnik v imenovalniku ali orodniku. V konkretnem besedilu pa bo besedna oblika imela seveda samo eno pravilno oznacbo. Naloga programov za oblikoslovno oznacevanje je, izmed moznih oblikoslovnih oznacb neke besede glede na sobesedilo dolociti njeno pravo oznacbo.
Izdelanih je bilo ze vec oznacevalnikov, ki se lahko naucijo zakonitosti nekega jezika iz rocno oznacenih korpusov. Najbolj odmeven je bil verjetno t. i. oznacevalnik Xerox [3], ki z uporabo skritih oznacevalnih verig doloci najbolj verjetno zaporedje oblikoslovnih oznacb besed v nekem stavku. Program ne zivaja skladenjske analize, pac pa izkorisca lokalni kontekst besede za dolocitev njene oznake. Za angleski jezik jezik doseze ta in njemu podobni oznacevalci priblizno 95 % natancnost. Za slovanske jezike je, kot kazejo preliminarni rezultati za ceski jezik [8], ta natancnost verjetno manjsa, in sicer priblizno 82 %.
Povsem drug nacin oznacevanja je mogoce uporabiti pri vzporednih korpusih. Tu je koristno dolociti, kateri del originalnega besedila ustreza kateremu delu prevoda. Taksna paralelizacija je lahko bolj ali manj natanca: dolocimo lahko npr. samo povezave po poglavjih ali pa vse do povezav konkretnih besed v besedilu z njihovimi prevodi. Tudi tu je mogoce s statisticnimi metodami doseci zadovoljive rezultate. Eden bolj zanimivih taksnih programov je opisan v [5]. Njegova odlika je predvsem enostavnost, saj samo iz stevila znakov sklepa na najbolj verjetno povezavo med stavki originala in stavki prevoda. Tako z enostavnim orodjem dosezemo ze precej koristen nivo paralelizacije.
Vsem programom za jezikovno oznacevanje je skupno, da je njihova tocnost manj kot popolna. Za kakovosten korpus je zato koristno, da so dobljene oznake se rocno pregledane. Vendar pa to za velike korpuse postaja skorajda nemogoce, po drugi strani pa tudi ljudje ne oznacujejo popolnoma tocno. Poleg enostavnih napak je problem tudi v tem, da vsako oznacevanje predstavlja interpretacijo besedila, ta pa se lahko od cloveka do cloveka razlikuje.
3.3 Pregledovalniki
Kot primer konkordanc je v sliki 2 podano nekaj pojavitev besede mulatjera; korpus, iz katerega je bila ta konkordanca narejena, je racunalniska konferenca GORE iz omrezja SLON. Kot zanimivost se povejmo, da te besede ne najdemo niti v Verbincevem Slovarju tujk niti v Slovarju slovenskega knjiznega jezika.

Slika 2: Primer formata KWIC.
Bolj kot iskanje posameznih besed je zanimivo iskanje sobesedij. Te, ti. kolokacije, namrec lahko razkrijejo vezave besed tako s skladenjskega kot s pomenskega stalisca. Nacin pregledovanja je podoben kot pri KWIC, obstajajo pa tudi programi, ki avtomatsko izberejo sopojavitve, ki so statisticno in zato verjetno tudi jezikovno signifikantne. Moznost iskanja kolokacij je toliko bolj zanimiva za oznacene korpuse, saj tu lahko iscemo tudi sopojavitve bolj abstraktnih kategorij.
Koncno je tu se paralelno prikazovanje vzporednih korpusov. Prikaz je tipicno v dveh poravnanih (KWIC-) oknih, iskalni jezik orodij, ki taksne korpuse podpirajo, pa razsirjen tako, da se lahko kriteriji za iskanje nanasajo na vec vzporednih besedil. Natancneje ko so korpusi povezani, bolj podrobno je lahko taksno iskanje. Zanimivo je, da so vzporedni korpusi primerni tudi za enojezikovne raziskave. Tako npr. iskanje vseh pojavitev neke besede, katere prevod se ne pojavi v prevodu stavka, v katerem se beseda nahaja, hitro pokaze na idiomatske uprabe te besede.
Programe za prikazovanje korpusov je mozno kupiti, nekateri so pa tudi prosto dostopni. Vendar je zagotovitev ustreznega pregledovalnika se vedno problematicna, saj vsi ne tecejo na vseh racunalniskih platformah, imajo nepopolno funkcionalnost ali pa ne delujejo pravilno za slovenski jezik. Glede na veliko razsirjenost TEI za zapis korpusov se v zadnjem casu posebno pozornost posveca pregledovalnikom, ki delujejo nad oznacenimi korpusi SGML. Taksni pregledovalniki imajo prednost, da lahko izkoristijo vse oznake (npr. bibliografske) in da so v precej vecji meri jezikovno neodvisni.
4 MULTEXT-East
4.1 Korpus
1. vzporedni korpus, ki vsebuje roman 1984 G. Orwella v originalu in prevode v sestih jezikih projekta (priblizno 7 x 100.000 besed);
2. primerljiv korpus, sestavljen iz dveh nadaljnjih delov: prvi vsebuje sest leposlovnih del avtorjev iz drzav clanic projekta, drugi pa sest zbirk casopisnih clankov v jezikih teh drzav (priblizno 2 x 6 x 100.000 besed); slovenski del primerljivega korpusa je sestavljen iz romana Galjot D. Jancarja in 45 clankov iz casopisa Dnevnik;
3. govorjeni korpus, sestavljen iz 40 krajsih odlomkov iz evropskega projekta EUROM, prevedenih v sest jezikov projekta (priblizno 7 x 2.500 besed), prebranih in digitaliziranih, pri cemer bo ta govorjeni korpus poravnan s svojim ortografskim zapisom.
Celoten korpus je oznacen po priporocilu CES; poleg bibliografskih bodo oznake vsebovale strukturne informacije (odstavki, clanki, naslovi, premi govor, itd.) ter dolocene ťposebne besedeŤ, npr. lastna imena in okrajsave. Kot primer, kako taksne oznacbe izgledajo, sta v sliki 3 podana dva odlomka iz slovenskega in ceskega prevoda romana 1984.

Slika 3: Slovenska in ceska odlomka iz ť1984Ť.
Del korpusa bo tudi dodatno oznacen: vsi prevodi 1984 bodo stavcno poravnani z originalom, medtem ko bo del korpusa oznacen se z oblikoslovnimi oznakami.
4.2 Oblikoslovje: definicija, slovar, oznacevanje
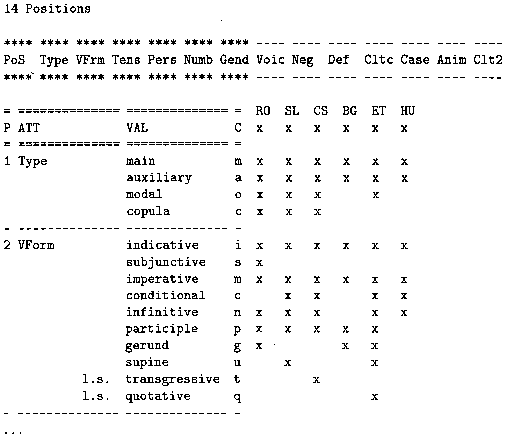
Slika 4: Zacetek MULTEXT-East tabele za glagol.
Ker je projekt vecjezikoven, je potrebno oblikoslovne oznake definirati v skupnem formatu za sest jezikov. Kot primer iz MULTEXT-East 'slovnice' je v sliki 4 podan zacetek tabele za glagole: ta doloca, da glagolsko besedo opisuje 14 lastnosti. Najprej je podana besedna vrsta (tj. glagol, V), v tabeli pa vidimo definicijo prvih dveh lastnosti glagola; za vsako lastnost je podano ime ter nabor njenih vrednosti. Imenu vrednosti sledi njena enocrkovna koda le-te ter dolocitev, katere jezike opisuje. Tako npr. slovenscina loci glagolske oblike povednika, velelnika, pogojnika, nedolocnika, deleznika ter namenilnika.
Ze iz zgornjega bo jasno, da dolocitve MULTEXT-East za oblikoslovje mestoma odstopajo od tradicionalnih kategorij v slovenskih slovnicah; tako so npr. glagolska delezja in glagolniki razvrsceni med prislove in samostalnike. Taksna odstopanja so v veliki meri posledica usklajevanja zapisov sestih med seboj zelo razlicnih jezikov, posredno pa dvanajstih, saj so tabele usklajene tudi z jeziki MULTEXT.
Predstavljeni format ima to prednost, da je neko oblikoslovno oznako mogoce zapisati v kompaktnem, obenem pa se vedno berljivem (ASCII) zapisu: tako npr. niz Vmip3s doloca vrednosti Verb main indicative present third singular oz. povednik glavnega glagola v tretji osebi ednine.
Naslednji korak je izdelava slovarjev, ki bodo v MULTEXT-East vsebovali 15.000 gesel za vsakega od sestih jezikov projekta. Ti slovarji poleg samih korpusov predstavljajo tudi pomemben vir jezikovnih podatkov.

Slika 5: Fragment MULTEXT-East slovarja.
Slovarji imajo preprosto, pa vendar precej informativno strukturo: vsak vnos je sestavljen iz besedne oblike, njenega gesla ter njenih oblikoslovnih znacilnosti. Primer vnosov za besedno obliko beraci je podan v sliki 5.
S slovarjem je nato mogoce zaceti oznacevanje besed v korpusu. Glavni problem taksnega oznacevanja je seveda dvoumnost besednih oblik --- tako ima beraci stiri mozne interpretacije, od katerih bo na dolocenen mestu v besedilu samo ena pravilna.
Kot je bilo ze receno, je za avtomatsko dolocanje pravilne oznake mogoce uporabiti statisticne oznacevalnike, vendar pa ti potrebujejo rocno oznacen korpus za ucenje. Ker tak korpus za slovenski jezik (pa tudi za ostale jezike projekta, razen ceskega) ne obstaja, bo v okviru projekta potrebno rocno oznaciti del korpusa, nato pa v zaporedju vec korakov izsolati oznacevalec, rocno popraviti rezultate in postopek nato ponoviti na razsirjeni ucni mnozici. Ker oznacevalci potrebujejo velike ucne mnozice, rocno pregledovanje pa je izredno zamudno delo, bodo rezultati projekta tu samo pripravljalni. Verjetno bo rocno pregledan samo del korpusa, ker pa je potrebna velikost ucne mnozice odvisna tudi od stevila moznih oznak, bo stevilo oblikoslovnih oznak v besedilu zgosceno glede stevila slovarskih oznak.
4.3 Dostop do rezultatov projekta
S tem bo izdelanih nekaj osnovnih racunalniskih virov za slovenski jezik, ki bodo usklajeni z mednarodnimi standardi in priporocili ter s petimi drugimi jeziki projekta. Kljub temu da so ti viri premajhni za marsikatero aplikacijo, so vendarle pomembni, saj bodo prvi tovrstni siroko dostopni viri slovenskega jezika --- rezultati projekta bodo namrec v neprofitne namene dostopni zastonj. Vsaj za naso skupino na IJS pa so verjetno bolj kot izdelava samih virov pomembne izkusnje, ki smo jih pridobili pri projektu, saj predstavljajo osnovo, na kateri bi bilo mogoce zgraditi referencni korpus slovenskega jezika.
Za popularizacijo (rezultatov) projekta smo na IJS postavili WWW stran z naslovom http://nl.ijs.si/ME, ki vsebuje vse osnovne informacije o projektu, primere iz korpusa ter slovarjev, pa tudi vmesne rezultate projekta.
5 Zakljucek
Pravno vprasanje je izredno pomembno, posebno pri izdelavi, saj so besedila v korpusu se vedno last avtorjev, zalozb ali prevajalcev. Ti se ponavadi bolj ali manj upraviceno bojijo zaupati svoja besedila na racunalniskemu mediju urednikom korpusa in nato tretjim osebam, saj je, vsaj v teoriji, ta besedila nato mozno razmeroma enostavno ponatisniti ali kako drugace neavtorizirano uporabiti. Izkusnje evropskih projektov kazejo, da uredniki korpusov porabijo ponavadi skorajda vec casa za pridobitev privoljenj lastnikov besedil kot pa nato za izdelavo samega korpusa. Pravni status dodatno zapleta dejstvo, da korpus sestavljajo tudi oznake v njem, te pa so last urednikov korpusa.
Ce so uredniki korpusa tudi njegovi edini uporabniki, je neavtorizirana uporaba se relativno enostavno obvladljiva. Vendar pa utegne korpus biti zanimiv tudi tretjim osebam. Ob predpostavki, da lastniki besedil, pa tudi uredniki korpusov, zaupajo pravnemu sistemu svoje drzave, je mozno nezazeljeno izkoriscanje korpusov urediti z ustreznimi izjavami, s katerimi se morajo zavezati tako uredniki korpusov kot tudi nadaljnji uporabniki. Formuliranje taksnih izjav na sreco postaja vedno lazje, saj je na voljo ze dosti primerov iz evropskih projektov.
Seveda pa je izdelava korpusov, posebno siroko dostopnih, smiselna samo, ce se ti korpusi nato tudi uporabljajo. Tu stopi v ospredje cloveski dejavnik, saj dosti institucij, ki bi taksne korpuse lahko s pridom uporabljale, nima razvite racunalniske ekspertize. Verjetno je najlazji nacin, kako taksni jezikovni viri lahko zazivijo, uvajanje njihove uporabe v primerne visokosolske studije ter s popularizacijo celotnega podrocja jezikovnih tehnologij.
Kot je bilo ze receno, javno dostopnih in standardiziranih korpusov za slovenski jezik se ni. Izdelava korpusov in ostalih jezikovnih virov je predraga, da bi bilo smiselno ze v prvi fazi prepustiti njihov nastanek ekonomskim dejavnikom, se posebej za jezike s tako majhnim stevilom govorcev, kot jih ima slovenski jezik. Z vladnim financiranjem in sodelovanjem zalozb, racunalniskih his in akademskih institucij bi bilo nujno najprej omogociti izdelavo siroko dostopnih virov, saj sele ti lahko dajo eno od prepotrebnih osnov za nadaljnji razvoj raziskovanja in uporabe nase materinscine.
Literatura
[1] Vladimir Batagelj (1995). Uvod v SGML. URL: http://vlado.mat.uni-lj.si/vlado/sgml/sgmluvod.htm.
[2] Eugene Charniak (1994). Statistical Language Learning. Language in Computers 12. The MIT Press.
[3] D. Cutting, J. Kupiec, J. Pedersen in P. Sibun (1992). A Practical Part-of-Speech Tagger. V: Proceedings of the Third Conference on Applied Natural Language Processing, str. 133-140, Trento, Italija.
[4] Tomaz Erjavec, Nancy Ide, Vladimír Petkevic in Jean Véronis (1996). Multext-east: Multilingual Text Tools and Corpora for Central and Eastern European Languages. V: Proceedings of the First TELRI European Seminar: Language Resources for Language Technology, str. 87-98.
[5] William Gale in Ken W. Church (1993). A Program for Aligning Sentences in Bilingual Corpora. Computational Linguistics, 19 (1): 75-102.
[6] R. Garside, G. L. Leech in G. Sampson (uredniki) (1987). The Computational Analysis of English. London in New York: Longman.
[7] Charles F. Goldfarb (1990). The SGML Handbook. Oxford: Clarendon Press.
[8] Barbora Hladka in Jan Hajic (1996). Tagging a Highly Inflected Language. V: Proceedings of the First TELRI European Seminar: Language Resources for Language Technology, 191-196.
[9] Miran Hladnik (urednik). Zbirka slovenskih leposlovnih besedil. URL: http://www.ijs.si/lit/leposl.html.
[10] Nancy Ide, Greg Priest-Dorman in Jean Véronis (1996). Corpus Encoding Standard V1.3. Tehnicno porocilo, Eagles, Multext & Multext-East, http://www.cs.vassar.edu/CES/CES1.html.
[11] Nancy Ide in Jean Véronis (urednika) (1995). The Text Encoding Initiative: Background and Context. Dordrecht: Kluwer Academic Publishers.
[12] Henry Kucera in William Nelson Francis (1967). Computational Analysis of Present Day American English. Rhode Island: Providence, Brown University Press.
[13] John Sinclair (urednik) (1987). Looking Up: An account of the COBUILD Project in lexical computing. Collins.
[14] John Sinclair (1994). Corpus Typology. EAGLES DOCUMENT EAG--CSG/IR--T1.1, Commission of the European Communities.
[15] C. M. Sperberg-McQueen in Lou Burnard (urednika) (1994). Guidelines for Electronic Text Encoding and Interchange. Chicago and Oxford.
[16] Joze Toporisic (urednik) (1975). Besedila slovenskega jezika. Ljubljana: Filozofska fakulteta.
